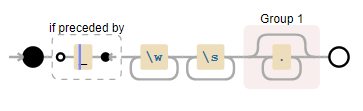
我想在字符串中计算紧跟在一个下划线后的未知数量的单词。
testString = '21 High Street _Earth Mighty Motor Mechanic'
我可以通过非捕获组 (?:\s[a-zA-Z]+) 来匹配这些单词,但目前无法构建正则表达式以排除下划线前的部分。你可以在这个<a href="https://regex101.com/r/ULGx0d/1" rel="nofollow noreferrer">演示链接</a>中看到这个表达式的效果。
我的目标是在Python脚本中使用完整的模式,如下所示:
import re
# 修改后的正则表达式,从下划线后开始匹配
pattern = r'_\s*([a-zA-Z]+(?:\s+[a-zA-Z]+)*)'
results = re.findall(pattern, testString)
if results:
answer = len(results[0].split()) # 分割匹配结果并计算单词数